“新概念英语”、“可可英语”、“亚马逊的audible有声书”、“扇贝听力”是我目前所知道的实现英文语音和文本同步的应用。 “同步”包括两方面:
- 被读到的单词(或句子)可以高亮显示,同步显示文本;
- 选中某个单词(或句子)跳到对应的音频位置播放;
想要实现同步,需要知道每个单词(或句子)在音频中的位置,称之为时间戳,类似于
if(1.905669,2.0353742) you(2.0353742,2.1650794) really(2.1650794,2.4444444) want(2.4444444,2.643991) hear(2.643991,2.9333334) about(2.9333334,3.2226758) it(3.2226758,3.3024943)
手动去做显然是件非常费力的工作,幸运的是,已经有研究人员实现了该功能,并且开源了软件: CMUSphinx Long Audio Aligner 项目主页
The aligner takes audio file and corresponding text and dumps timestamps for every word in the audio. (aligner可以根据音频和相应的文本,产生音频中每个字的时间戳)
还有人做了进一步处理,把CMUSphinx生成的timing file格式化为一个json文件,这样:它的github主页
"words": [
["if", 1.905669, 2.0353742], ["you", 2.0353742, 2.1650794], ["really", 2.1650794, 2.4444444], ["want", 2.4444444, 2.643991], ["hear", 2.643991, 2.9333334], ["about", 2.9333334, 3.2226758], ["it", 3.2226758, 3.3024943],
又有人在上两者的基础上实现了一个网页版的同步有声书:HTML5 Audio Karaoke – a JavaScript audio text aligner 点击这里可以观看它的Demo
而我希望做一个具有这样功能的android app,播放自己喜欢的英文小说,练习听力。
如何使用Long Audio Aligner
$ git clone git@github.com:li2/TalkingBook21_AudioSync.git
$ cd aligner
$ python align-wav-txt.py demo/Unsigned8bitFormat.wav demo/raw.txt
Running ant
Updating batch
Aligning text
Transcription: pumas are large catlike animals which are found in americawhen reports came into london zoo......
# --------------- Summary statistics ---------
Total Time Audio: 112.00s Proc: 3.28s Speed: 0.03 X real time
<unk>(0.0,0.49) are(1.88,1.91) large(2.07,2.31) animals(2.34,2.94) which(2.94,3.15) are(3.15,3.29) found(3.29,3.67) in(3.67,3.76) americawhen(3.76,4.39) reports(5.22,5.92) came(5.92,6.3) into(6.33,6.66) london(6.66,7.09) zoo(7.09,7.42)......
# you can also execute:
$ python align-mp3-txt.py demo/OtherFormat.mp3 demo/raw.txt
这是一个命令行工具,它最终执行的是jar -jar bin/aligner.jar your/audio/file your/txt/file,python脚本align-wav-txt.py在其基础上做了一层封装。
这里需要特别强调的是,aligner对音频文件特别挑剔,遇到过的问题之一:耗尽计算机CPU,甚至超频,最后java内存溢出。
PID COMMAND %CPU TIME #TH #WQ #PORT MEM PURG CMPRS PGRP PPID STATE BOOSTS
17203 java 718.4 64:34.94 30/8 0 95 4276M- 0B 51M 17203 15729 running *0[7]
$ ps aux | grep 17203
weiyi 17203 658.3 26.2 8298480 4392764 s000 R+ 10:07上午 76:11.30 /usr/bin/java -jar bin/aligner.jar ../demo.wav ../demo.txt
Exception in thread "main" java.lang.OutOfMemoryError: GC overhead limit exceeded
at edu.cmu.sphinx.decoder.search.AlignerSearchManager.collectSuccessorTokens(AlignerSearchManager.java:584)
问题二:只能同步一小部分文本。 下面是我对网上下载的新概念英语3做的测试:
(章节号) 同步文本的时长/总时长
01 123/129
02 115/122
03 129/136
07 81/129
08 74/136
09 17/146
10 6/150
12 117/130
13 44/123
04,05,06,11,14,15,16,17,19,20,21,22,24,27 Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException
18 54/140
23 171/178
25 0~100缺失
26 144/190
这两个问题应该都和音频格式有关。音频编辑软件audacity可以导出音频为不同的格式,经过对比测试时发现,在导出对话框的format选项中,选择“其它非压缩音频文件:文件头WAV(Microsoft), 编码Unsigned 8 bit PCM”,这种音频格式能够得到最佳的结果。
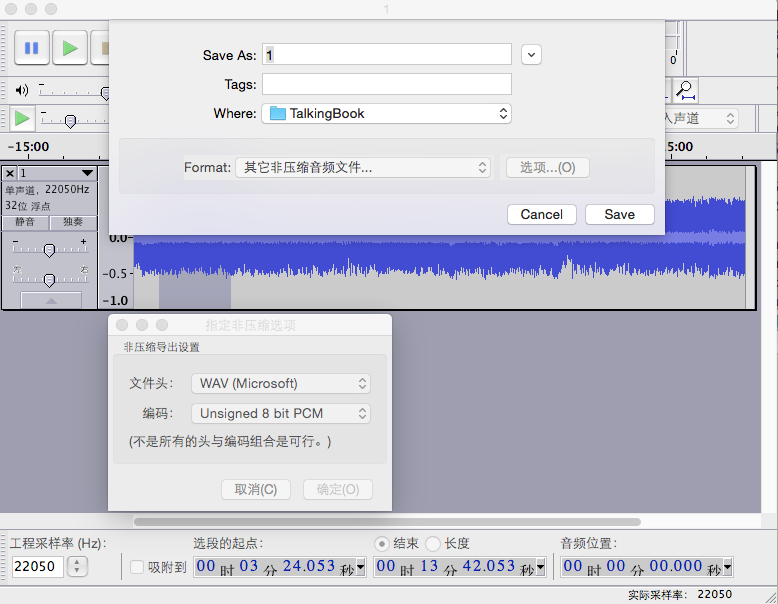
所以我在demo文件夹里上传了两种格式的音频文件,用以对比。
google 关键字
audio text alignment, audio text sync
aligner 依赖环境
Python 2.7, java, ant, sox,
如果你在执行脚本的过程中,遇到错误,需要根据错误提示搜索原因并安装相关包,比如ubuntu12.04环境下执行align-mp3-txt.py时,提示错误:
no handler for file extension `mp3'
需要安装libsox-fmt-mp3
处理Long Audio Aligner生成的Timing File
插入缺失的文本和标点符号
细心的你可能已经发现aligner生成的timing file实际上是根据音频文件转译的文本,与原始文本相比:无标点符号(包括段落分隔符);错字(youre, dont, isnt之类缺失');漏字,等等。
于是我写了一个python脚本parse_timing_json.py,它比较原文和aligner输出的json文件,把原文未被识别的文本插入到json文件中,得到一个包含完整文本和时间的json文件.
但是,这个脚本容错性非常不好,或者说,对输入文件非常挑剔,输入json文件漏字不能太多,和txt文件必须几乎一致,这个脚本才可以把时间戳和原文做匹配。 幸运的是,long-audio-align产生的json文件可以满足。
处理换行符和超过行宽的字符串
如果json文件中的字符串包含换行符,则以换行符为界拆分字符串,换行符单独拿出来。目的是方便app处理换行:app读取到换行符后,使其占据整个linearlayout,使app所显示的文本段落结构更加清晰。 另外,如果字符串包含的字符个数超过5个,则拆分这个字符串。
# 如果你能正确执行align-wav-txt.py,那么你会在demo文件夹中得到一个名为raw.json的文件(一定要使用align-wav-txt.py参生的完整的json文件):
$ cd parse_timing_json/
$ python parse_timing_json.py ../aligner/demo/raw.json ../aligner/demo/raw.txt
# 生成文件raw.json.out.json,
$ python parse_new_line.py ../aligner/demo/raw.json.out.json
# 生成文件raw.json.out.json.out.json
对比处理前后的json文件:
处理前:
["are", 1.88, 1.91], ["large", 2.07, 2.31], ["animals", 2.34, 2.94], ["which", 2.94, 3.15], ["are", 3.15, 3.29], ["found", 3.29, 3.67], ["in", 3.67, 3.76], ["americawhen", 3.76, 4.39], ["reports", 5.22, 5.92],
处理后:
["are", 2.07], ["large", 2.07], [", cat- like animals", 2.34], ["which", 2.94], ["are", 3.15], ["found", 3.29], ["in", 3.67], ["America. When reports", 5.22],
一个android英文有声读物app
在得到了比较完整的timing file之后,剩下的工作是,如何呈现它。 初步构想是按页呈现文本,支持自动翻页和手动翻页,通过ViewPager和Fragment实现。所以问题是: 给定一个文本,如何拆分成页(每页铺满屏幕)? 比如可以拆分为3页,第1页包含21个单词,第2页包含22个单词,第3页包含23个单词。如果得到这些数据,那么就非常容易构建界面了。
构建拆分文本的Adapter
public class ChapterPageAdapter extends FragmentPagerAdapter {
// ViewPager的adapter的构造器,以文本文件的Uri作为参数。
public ChapterPageAdapter(Context context, FragmentManager fm, Uri jsonUri) {
super(fm);
mAppContext = context;
assert context != null;
mJsonUri = jsonUri;
mPageBeginningWordIndexList = new ArrayList<Integer>();
mPageBeginningWordTimmingList = new ArrayList<Integer>();
splitChapterToPages(mJsonUri);
}
// 在拿到文本后,通过下面两个private函数拆分文本,
// 而拆分的关键是,根据屏幕的宽度、高度,每个单词的宽度,计算一个屏幕可以显示的单词个数,用到的一些计算宽高度的方法被抽象成一个独立的类`ChapterPageUtil.class`,
// 最终得到每页首单词在文本中的序号。
private void splitChapterToPages(Uri jsonUri) {}
private int totalWordsCanDisplayOnOnePage(List<String> words, int startIndex) {}
@Override
public int getCount() {
// ViewPager托管的Fragment个数。
return 首单词序号的个数;
}
@Override
public Fragment getItem(int poisition) {
......
// 这就是ViewPager第position页需要显示的内容。
ChapterPageFragment fragment = ChapterPageFragment.newInstance(uri, fromIndex, count);
return fragment;
}
每页是一个Fragment
public class ChapterPageFragment extends Fragment implements OnClickListener {
// Create fragment instance
// 每页对应一个Fragment,需要告知它要显示的文本,从哪个单词开始显示,总共显示几个单词。
public static ChapterPageFragment newInstance(Uri jsonUri, int fromIndex, int count) {
Bundle args = new Bundle();
args.putString(EXTRA_TIMING_JSON_URI, jsonUri.toString());
args.putInt(EXTRA_FROM_INDEX, fromIndex);
args.putInt(EXTRA_COUNT, count);
ChapterPageFragment fragment = new ChapterPageFragment();
fragment.setArguments(args);
return fragment;
}
// Fragment是LinearLayout布局,
// 每个单词对应一个TextView,添加到 sub LinearLayout,填满后再添加到下一个 sub LinearLayout(对应下一行);
// 每个换行符独占一个 sub LinearLayout。
public View onCreateView(LayoutInflater inflater, ViewGroup container, Bundle savedInstanceState) {}
实例化文本为一个singleton
考虑到ViewPager Adapter和所有的Fragment都要用到文本信息,我们把文本实例化为singleton,便于文本数据取用。
public class TalkingBookChapter {
// Singletons and centralized data storage
private static TalkingBookChapter sChapter;
// Setting up the singleton
public static TalkingBookChapter get(Context context, Uri timingJsonUri) {
if (sChapter == null) {
sChapter = new TalkingBookChapter(context, timingJsonUri);
}
return sChapter;
}
private TalkingBookChapter(Context context, Uri timingJsonUri) {}
// 下面两个函数就是为了Fragment取它所需要显示的文本。
public List<String> getWordList(int fromIndex, int count) {}
public List<Integer> getTimingList(int fromIndex, int count) {}
public int size() {}
如何在点击单词或者翻页时跳转到对应的音频位置
Fragment定义一个interface,在TextView被点击时调用,Activity实现它完成音频位置的调节。 翻页的时候,就更简单了,只需要override ViewPager的OnPageChangeListener.
public class ChapterPageFragment extends Fragment implements OnClickListener {
private OnWordClickListener mOnWordClickListener;
public void setOnWordClickListener(OnWordClickListener l) {
mOnWordClickListener = l;
}
public interface OnWordClickListener {
public void onWordClick(int msec);
}
@Override
public void onClick(View v) {
if (v instanceof TextView) {
int msec = (int)v.getTag();
if (mOnWordClickListener != null) {
mOnWordClickListener.onWordClick(msec);
}
}
}
}
public class FullScreenPlayerActivity extends FragmentActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
mChapterPageAdapter = new ChapterPageAdapter(this, getSupportFragmentManager(), mTimingJsonUri);
mChapterPageAdapter.setOnChapterPageWordClickListener(mOnPageAdapterWordClickListener);
mChapterViewPager.setAdapter(mChapterPageAdapter);
// 这个Activity管理ViewPager,Fragment定义的interface被ViewPager的Adapter又包了一层,
// 所以当Fragment的TextView被点击后,最终会调用到这里:
private OnChapterPageWordClickListener mOnPageAdapterWordClickListener = new OnChapterPageWordClickListener() {
@Override
public void onChapterPageWordClick(int msec) {
seekToPosition(msec); // 这个函数调用到 MediaPlayer.seekTo(int msec),调节到指定的音频位置。
}
};
private ViewPager.OnPageChangeListener mOnPageChangeListener = new OnPageChangeListener() {
@Override
public void onPageSelected(int position) {
......
seekToPosition(mChapterPageAdapter.getPageTiming(position)); // 翻页时,调节到指定的音频位置。
}
如何高亮当前读到的文本
public class FullScreenPlayerActivity extends FragmentActivity {
// 这是一个更新界面的定时任务,
private void updateProgress() {
runOnUiThread(new Runnable() {
@Override
public void run() {
int msec = mPlayerController.getCurrentPosition();
mChapterPageAdapter.seekChapterToTime(msec);
// check if seeking time is out of selected page, if true, then set ViewPager to current item.
// 如果已经读到下一页,那么执行ViewPager.setCurrentItem()
......
}
});
}
public class ChapterPageAdapter extends FragmentPagerAdapter {
// This method will be called to notify fragment to update view in order to highlight the reading word.
public void seekChapterToTime(int msec) {
mSeekingTime = msec;
notifyDataSetChanged(); // 调用这个方法后,getItemPosition()会被调用,我们在getItemPosition()中完成Fragment界面的更新。
}
@Override
public int getItemPosition(Object object) {
if (object instanceof ChapterPageFragment) {
// This method called to update view in order to highlight the reading word.
((ChapterPageFragment) object).seekChapterToTime(mSeekingTime);
}
return super.getItemPosition(object);
}
关于章节列表对应的类的说明 TODO
关于播放器的说明 TODO
用到的开源软件
android-UniversalMusicPlayer 这是一个开源的android音乐播放器,它的项目主页 我的播放器代码很多直接拿了它的一个文件 FullScreenPlayerActivity.java 点击查看
ViewPagerIndicator 这是一个开源的Android UI,用以标示ViewPager的页,就是常见的几个小圆点。 它的项目主页
audiosync 这个就是音频文本同步的开源命令行工具。它的项目主页。 但是呢,它包含上百兆的音频文件,在时好时坏的国外网站访问现实下,有时只有几kb的下载速度,我就folk它然后删掉它的音频文件。这样子。
去哪下载
2015年08月21日完成了1.0版本,App名字叫TalkingBook21(因为我叫li21嘛),你可以在这里下载App, 呐,它是这个样子的:

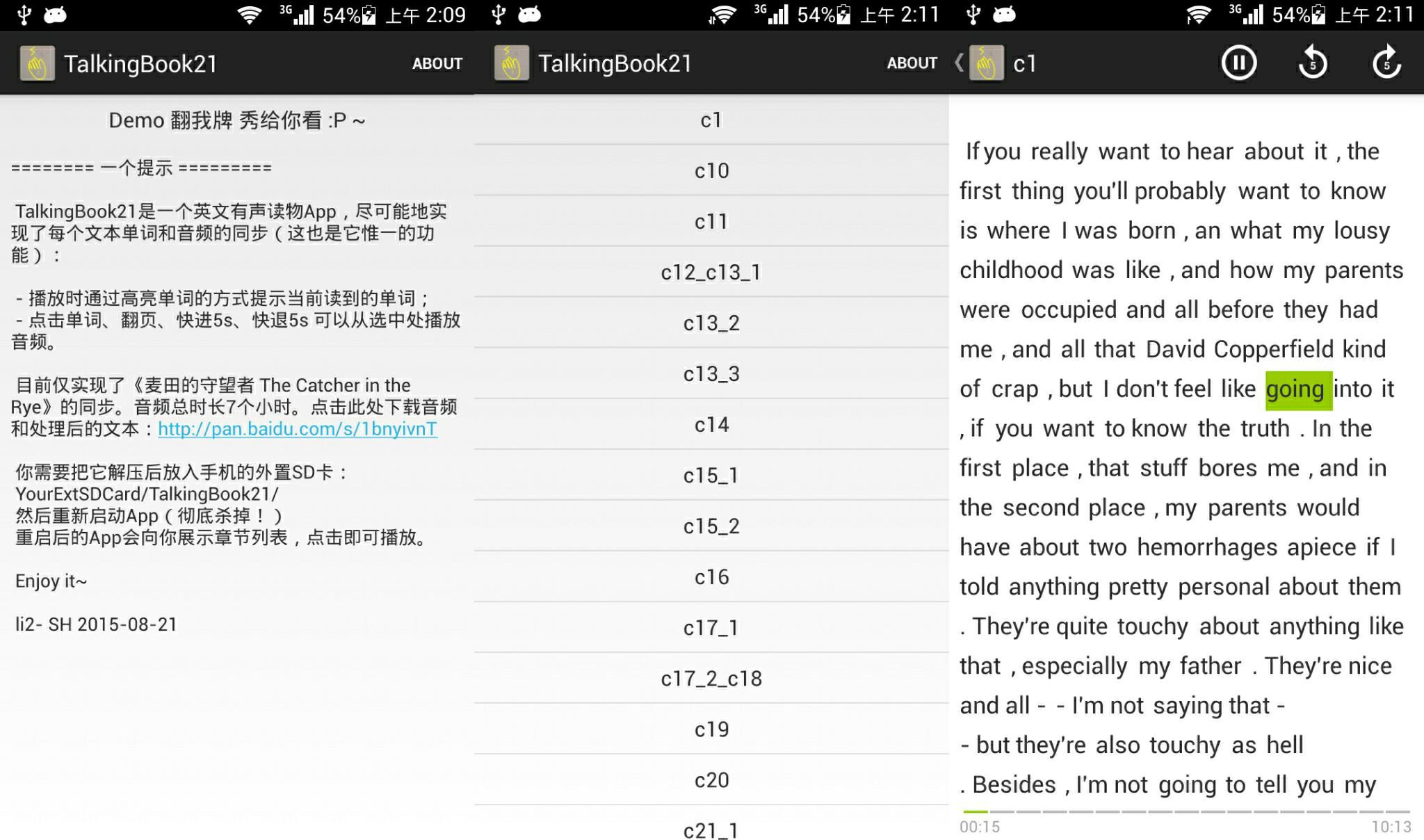
由于音频文件很大,所以只在app里包了一个音频,权当是个demo。 更多的音频需要在这里下载,目前仅实现了《麦田的守望者 The Catcher in the Rye》的同步,音频总时长7个小时,293M。 所以坦白的讲,这个app实质上是麦田的守望者音文同步有声读物Android App.
你需要把它解压后放入手机的外置SD卡:YourExtSDCard/TalkingBook21/,然后重新启动App(彻底杀掉!),重启后的App会向你展示章节列表,点击即可播放。
这里是app的源码 这里是制作timing json file的开源命令行工具
2015-05-31 ~ 2015-08-21