Android Jetpack: what's new in Architecture Components (Google I/O '18)

What is the problem LifeCycles want to solve?
Challenges
What is the hardest part of Android development? And by far in the list, big surprise, was lifecycle management. We're wondering, like, what can be hard about a phone rotating or user switching applications? This happens all the time on Android. Android is built for this. But if you look at the problem in detail, if you want to handle them properly in your application, you need to understand these state graphs very well. And when these two are interleaved, it becomes very confusing.
Fragment view's lifecycles
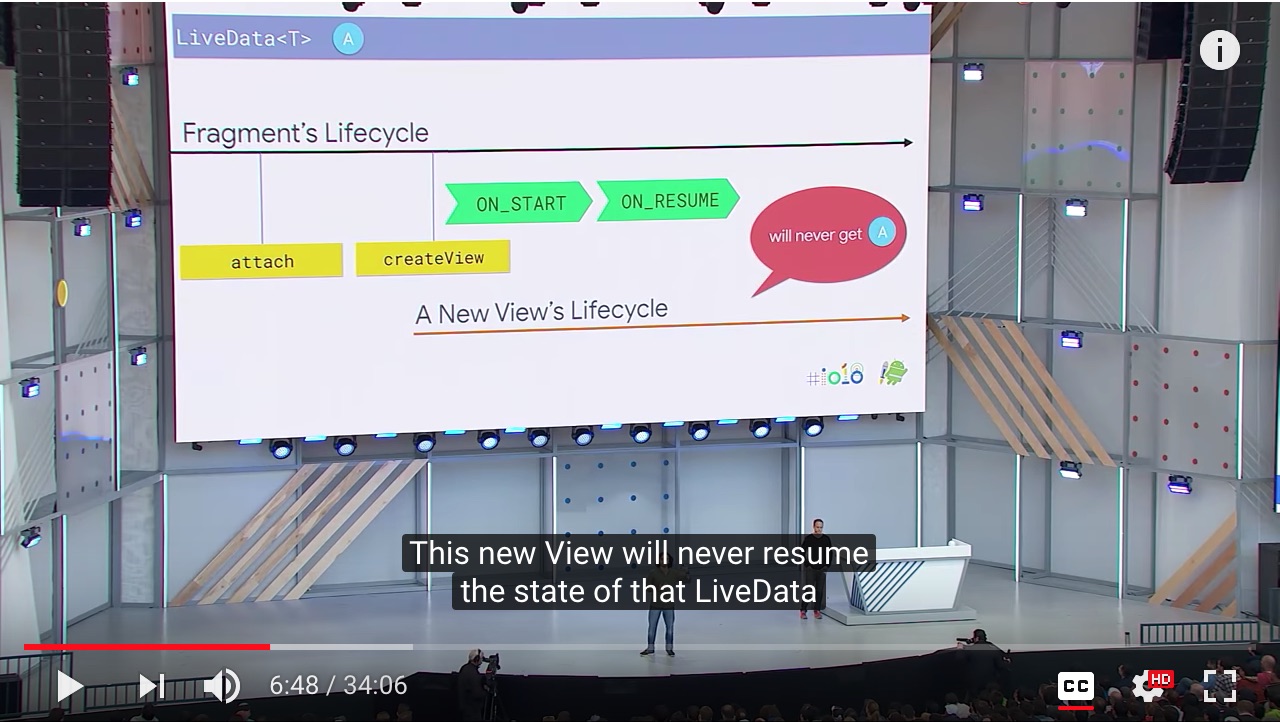
We will have a bug that the view will never resume the state of that LiveData if use the fragment lifecycle to observe the LiveData:
2 options:

The problem is that Fragment has 2 lifecycles, the solution is that give Fragment View its own lifecycle:
Data Binding -- Boilerplate free Android UIs
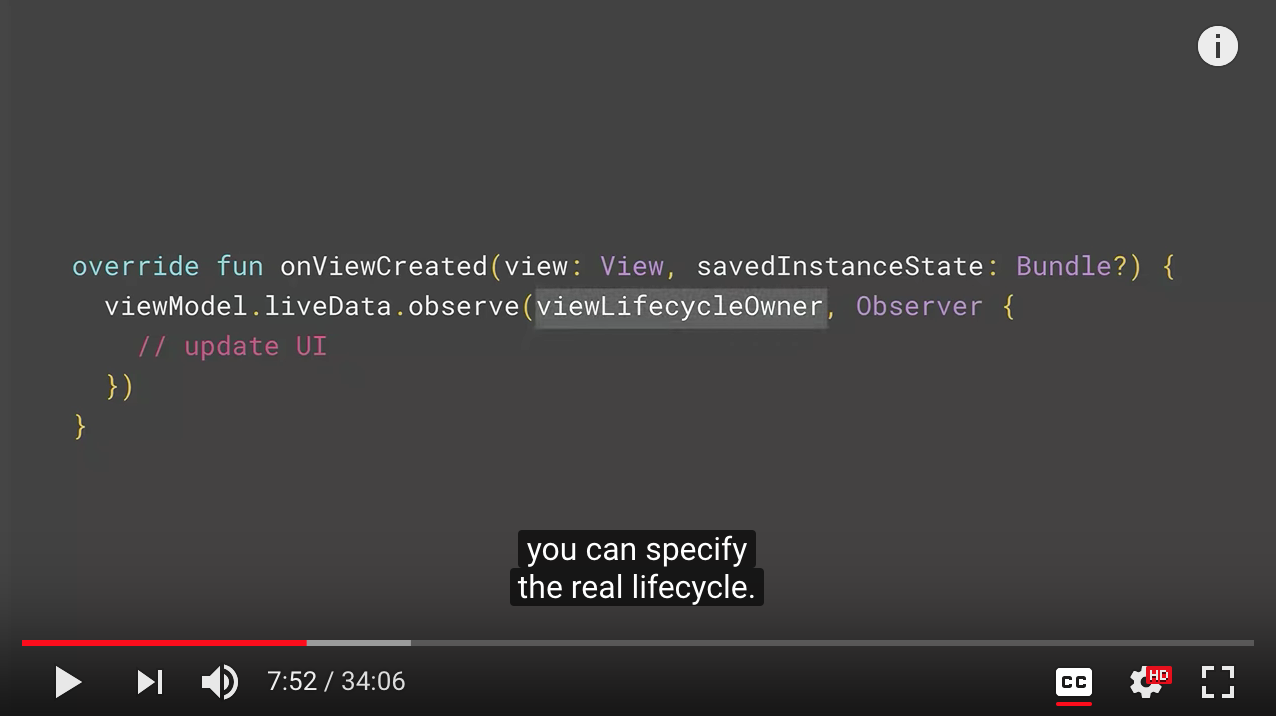
So if you're a view model like this, which has a LiveData for users, and if you pass it as a parameter to your binding, you can use that LiveData as if it's a regular field in your binding expressions. Data Binding will understand that is LiveData and generate the correct code. Unfortunately, this is not enough for it to observe it because Data Binding doesn't have a lifecycle. To fix that, when you get your binding instance, you just tell it which lifecycle it should use. It will start observing the LiveData to keep itself up to date.
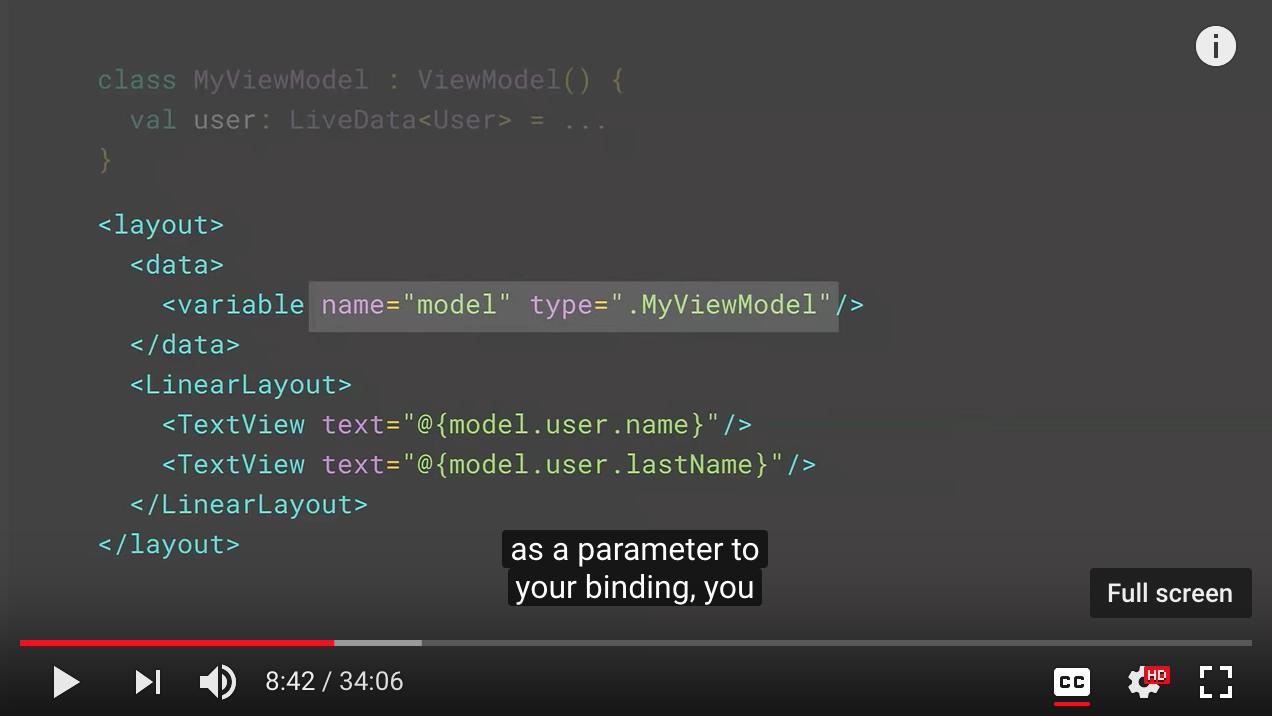
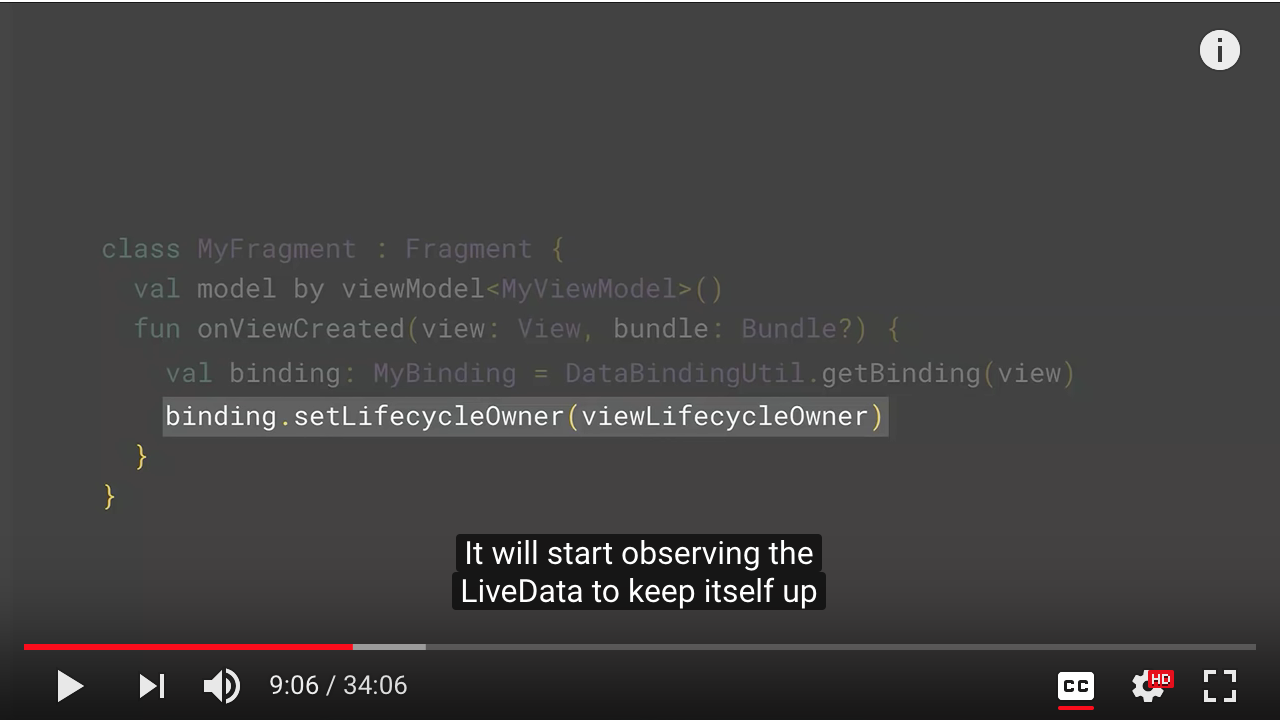
Question is that if the layout is reused with different ViewModels?
Room -- Object Mapping for SQLite Database
Room is our solution for object mapping that minds the gap between the SQL lite and your Java or Kotline code.
better multithreading
One important change we did in Room 1.1 was the support for better multithreading. So if you are using one Room 1.0, and if you have one thread that is trying to insert a lot of data into the database, and you have another thread that's trying to read data while the write is executing, your read will be blocked. And it can only execute after the write is complete. In Room 1.1 with writer logging, they can run in parallel now


@Query
But to better understand why we need RawQuery, let's talk about the Query annotation. Now, when you are using Room, you can specify your SQL query in this annotation. You can use the name bind parameters. You can pass those parameters as regular function arguments. And you can tell the Room what to return. The best part of this setup is that Room is going to validate all of this at compile time. So if there's a mistake in your query, if your parameters doesn't match, or what you try to return doesn't make sense, it's going to fail the compilation and let you know what is wrong.

Challenges
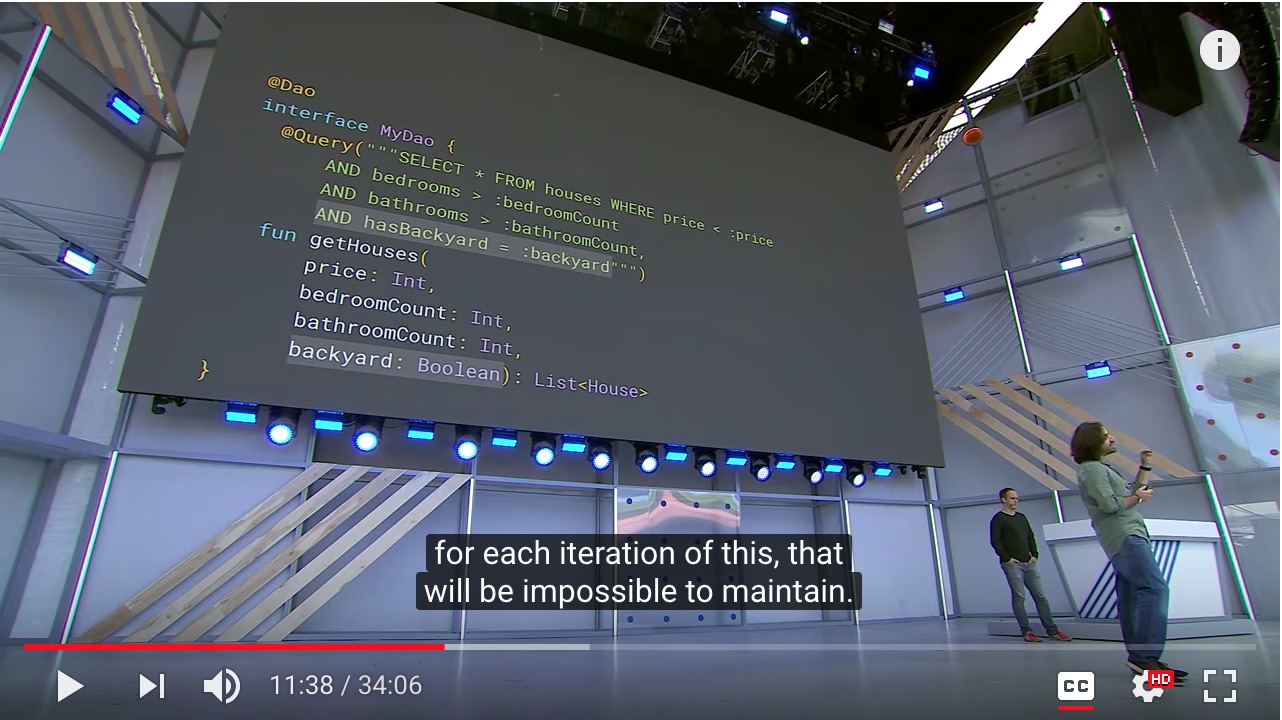
Now, this is all cool except what if you don't know the query at compile time? What if you're writing a real estate application, my user can search the houses with their price? Maybe they want to specify number of bedrooms, bathrooms, whether it has a yard. If you needed to query in a method for each iteration of this, that will be impossible to maintain.
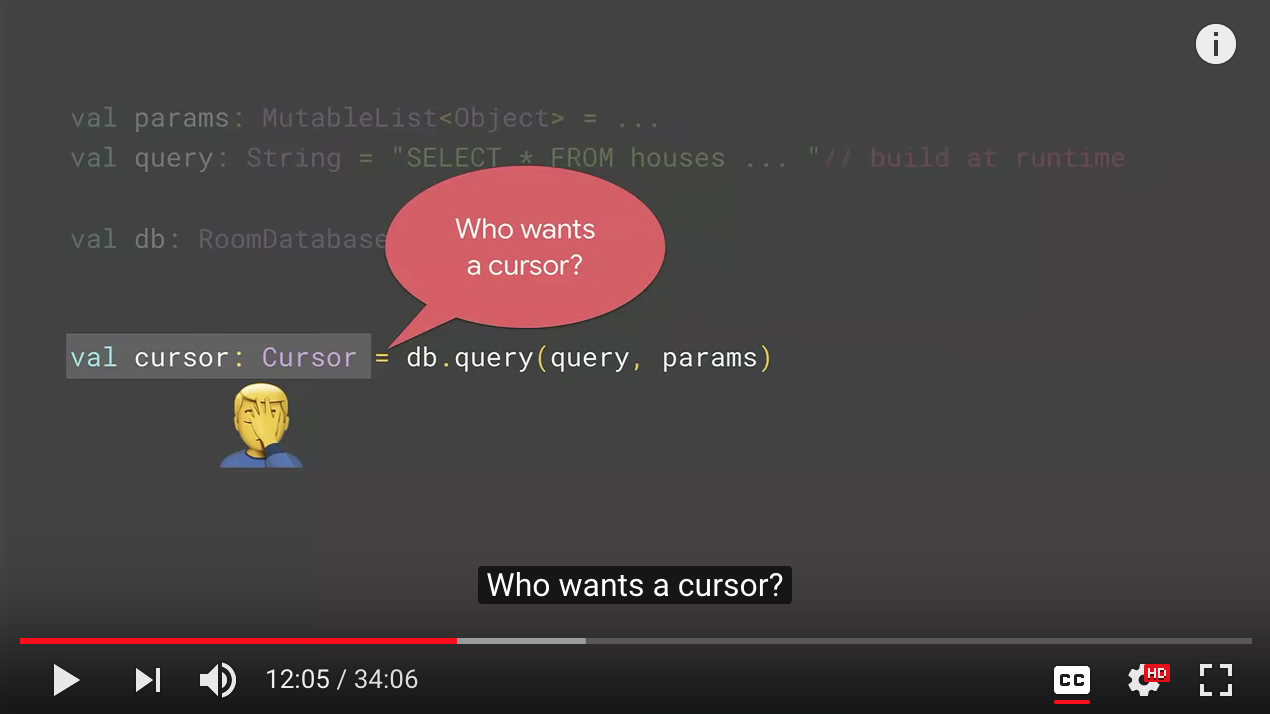
Cursor solutions? NO!
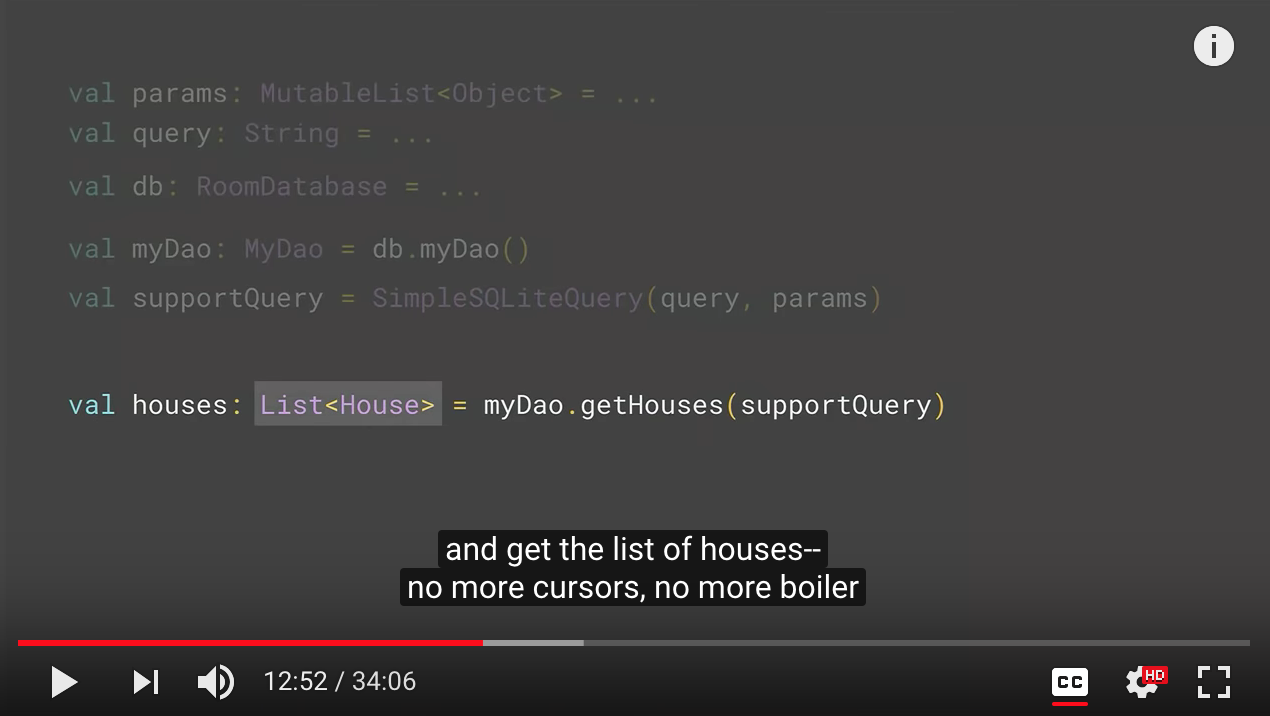
So what you do in this case is you create the query at runtime based on the options the user provided. And you prepare the arguments for that query. Now you obtain an instance of the Room database and use this query method to get the result. So far so good. The problem with this approach is that it returns your cursor.
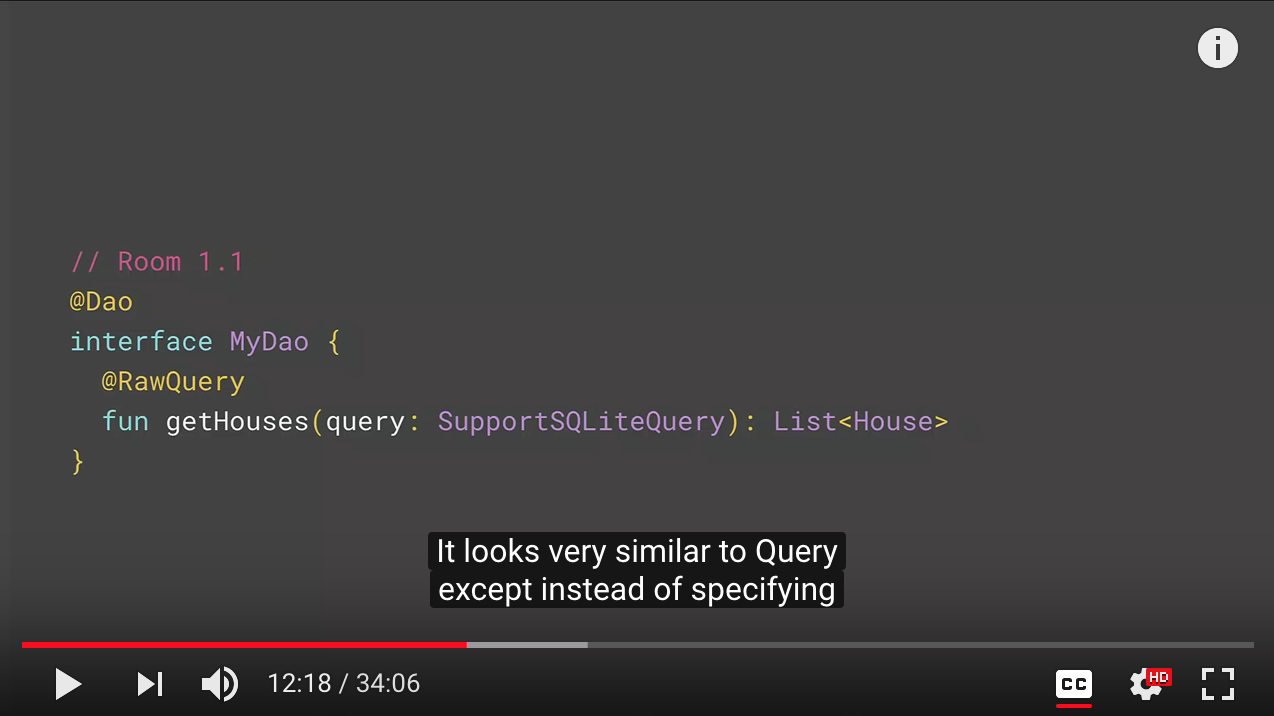
RawQuery Solution
Hence, we have decided to introduce RawQuery annotation. It looks very similar to Query except instead of specifying the query in the annotation, you pass it as a parameter to the function. And then you tell us what you want us to return. Now, here, Room cannot validate that query anymore. So it's kind of, you promised us to send the right query, and we'll take care of it. Once you have that, if you go back to our previous example, we can get an instance of our Dao. Now we need to merge our parameters and the query in this simplest guide query class, which is basic data holder. And then you can pass it through the Dao and get the list of houses-- no more cursors, no more boiler plate code.
Paging -- Lazy loading for RecyclerView
Challenges
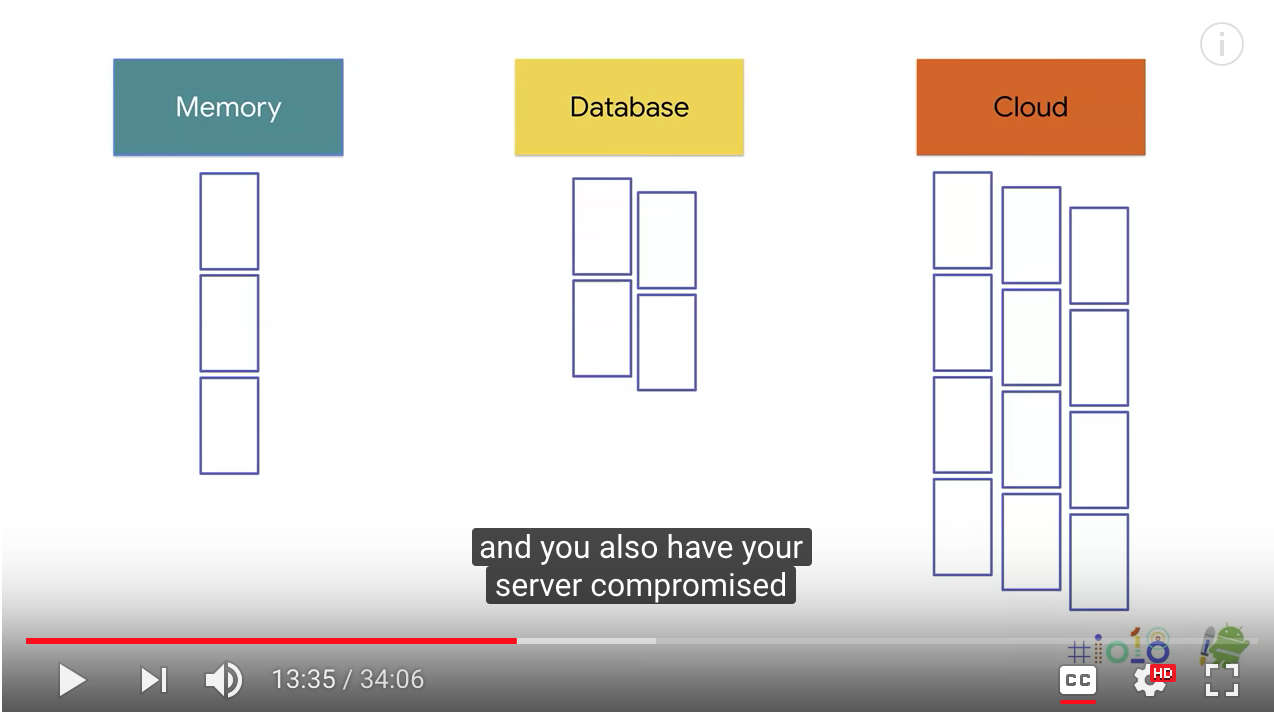
Paging is our solution for lazy loading in RecyclerView. But to better understand why we developed this component, let's go through an example. So you have a list like this. It's very common. Every single application has this. User can scroll. But you know, it actually represents a much larger list than what's on screen. And if you're an application like Twitter, for instance, it's a really, really long list. So you probably cannot fit it to memory, and it's also very inefficient to log all of it. So what you will do is you will keep some of it in memory, the rest of it in database, and you also have your server compromised where you pull this data from. Now, this is actually very hard to implement properly. That's why we have created the Paging Library to make these common falls very easy and efficient to implement.
Paging features:
- Supports both LiveData and RxJava
- From database
- From network
- From database + network
Navigation -- Easy in-app navigation
Challenges
But when you think about core problems that almost every app has to deal with, in-app navigation has to be close to the top of the list there. And that ranges from executing a Fragment transaction without throwing an exception, hopefully. Passing arguments from place to place, possibly even with type safety if you can figure that out. Testing the navigation is working and that the right things are happening when you navigate from place to place. Making sure that the up and back buttons work correctly and take the user where they're supposed to go. Mapping deep links to destinations in your app and having that work.

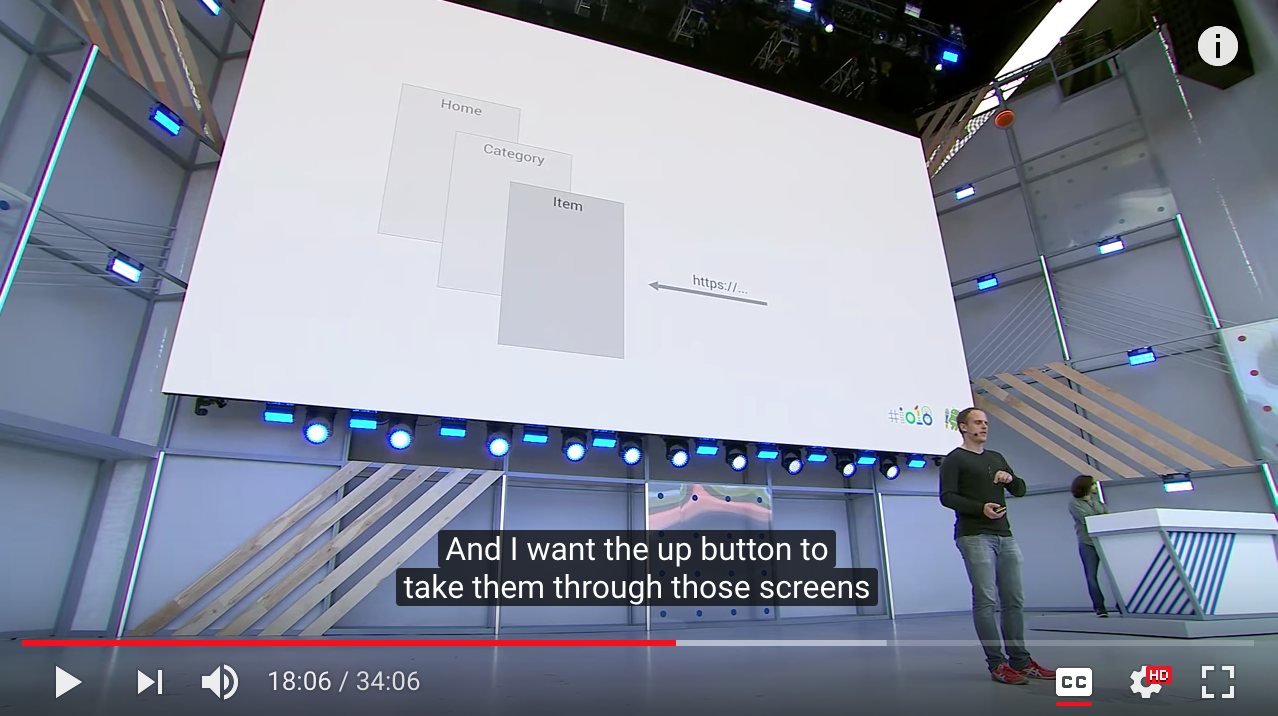
Deep Links challenges
say I have an item screened in my app, maybe a product screen. And that screen is accessible via Deeplink. But actually, there are other pages that if the user had navigated here by opening the app from the home screen, they would have come via the home screen, the category screen. And I want the up button to take them through those screens rather than exiting the app. So that means that if someone deep links into the app, I need to synthesize these screens and add them to the back stack, but only on a deep link.
Solution
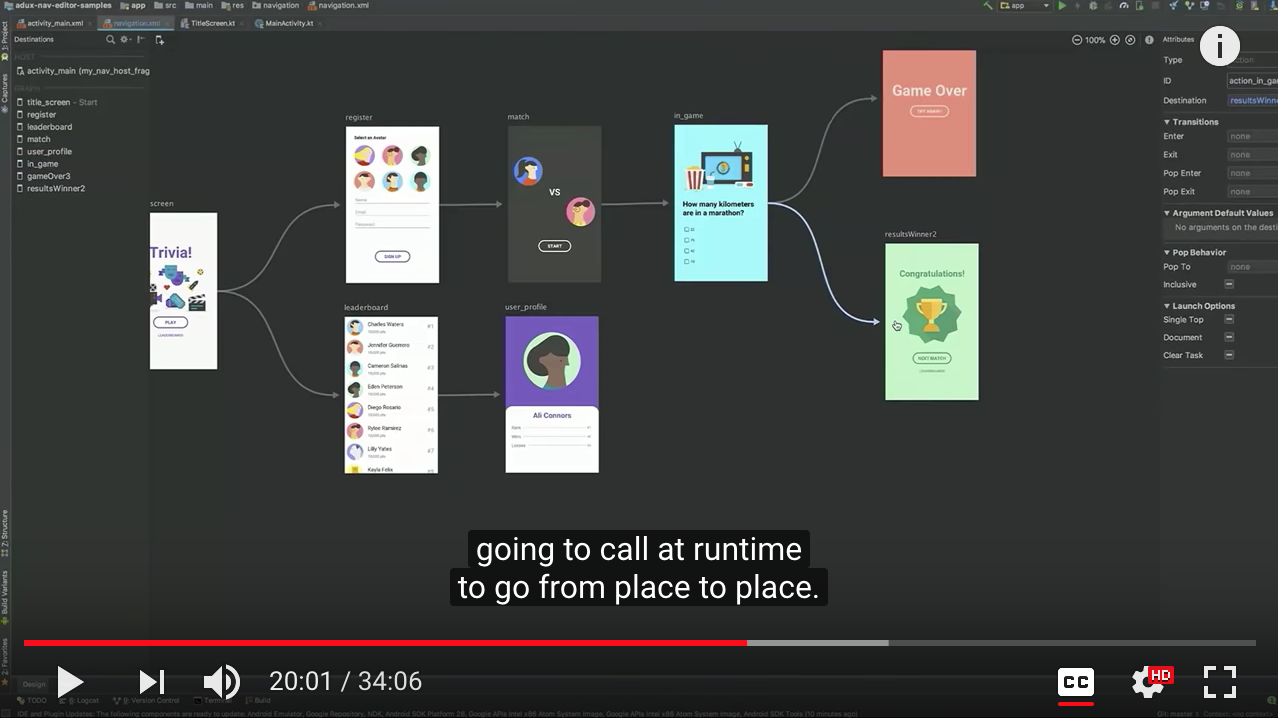
And so that's why we're really happy to be launching navigation, which is both a runtime component that performs navigation for you and a visual tool that works with XML to define the navigational structure of your app and then allows you to just navigate at runtime with a single navigate call.
You simply need to define in XML and then the navigation framework will handle at runtime for you are animations, passing arguments in a typesafe way from place to place, making sure that up and back work correctly, and mapping deep links to various screens in your app. And last but not least, no more Fragment transactions ever.
Work Manager -- Deferable guaranteed execution && Chain workers && Opportunistic execution
Challenges
For instance, if user decides to send a tweet, you want to send it now. But if there is no network connection, you want to send it as soon as device is connected to the internet. There's things like uploading logs you may want to do if the device is charging. Or you may want to periodically sync your data with your backup. Now, we know this is not a new problem on Android.
Solutions
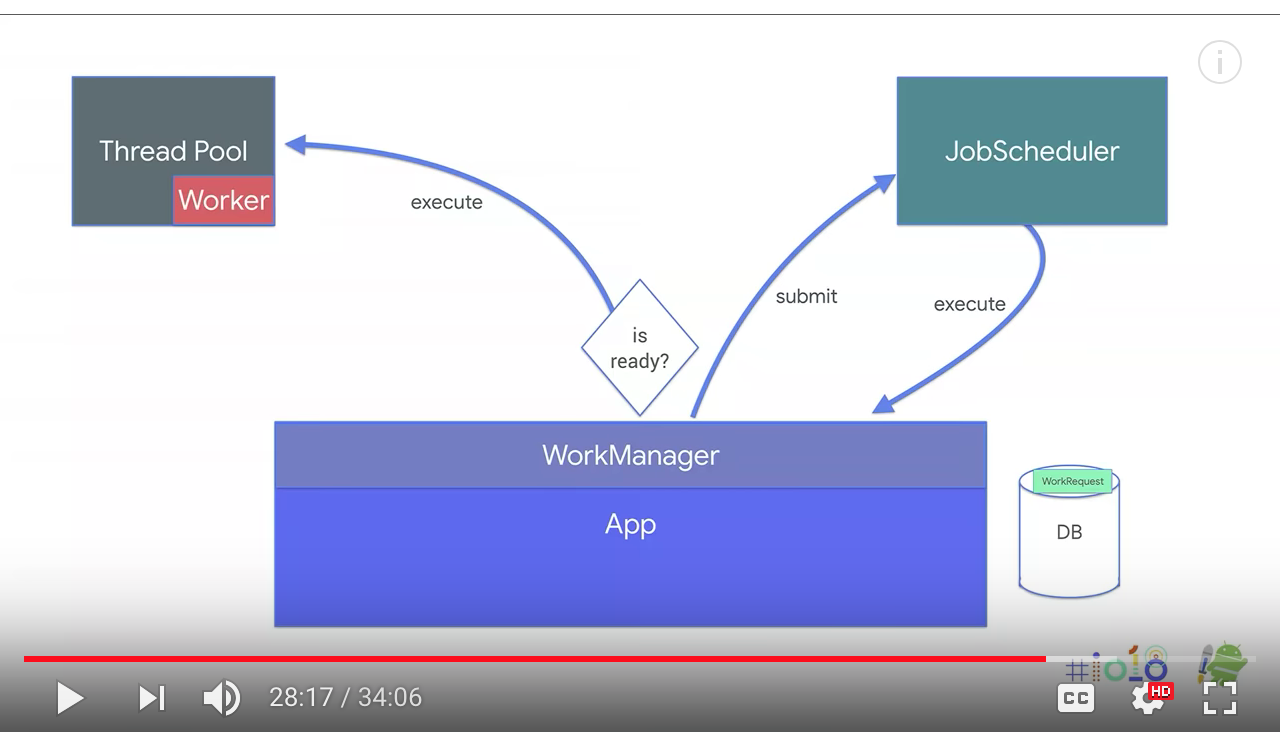
And we had some solutions for this. We have introduced JobScheduler in Lollipop. And we have Firebase JobDispatcher that back forced this functionality in the devices which has Google Play services. And we also have AlarmManager for exact timing. Now, each of these has different behaviors and different APIs. It becomes very hard to implement. Hence we have built WorkManager that sits on top of them and provides a much cleaner API with new functionalities. WorkManager has two simple concepts. You have the workers that execute these actions. And you have the work requests which trigger these workers.
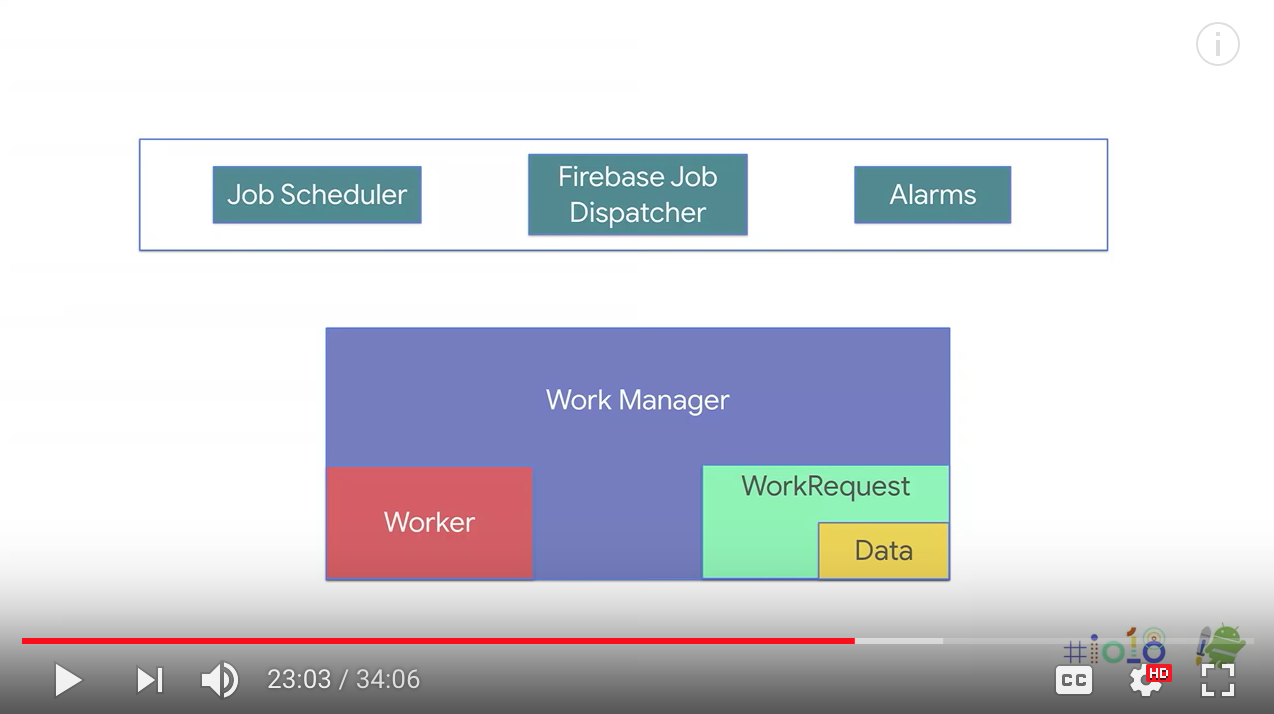
workers that execute these actions
this is basically all you do. You extend the worker class. You implement one function that says do the work. And that function just needs to return to us what happened as a result of that work. So you can do whatever you do, and you return the result. There is no services, no intents, no bundles, nothing like that.

worker requests which trigger these workers
Once we have the worker, we need to create a work request. So you can use this one time work builder. Or there's a periodic version of this one. You can specify the worker class. But now, you can also add constraints. You can tell it only run if there's network connection if the device is charging. Or you can specify a back off criteria. So if the worker is failing, how should we retry it? You can also pass input parameters to these workers. Once you build that work request, you can get an instance of WorkManager and inquiries. Now, WorkManager will take care of executing it.

chain your workers
One of the important distinctive features of WorkManager is that it has input and output semantics. So your workers can receive input, but they can also output some data. You could observe this data through WorkManager. But it was actually really useful to chain your workers. So imagine you have an application where user picks an image for their device. Now you want to run some image processing on that picture. And then once it's done, you want to upload it to your server.
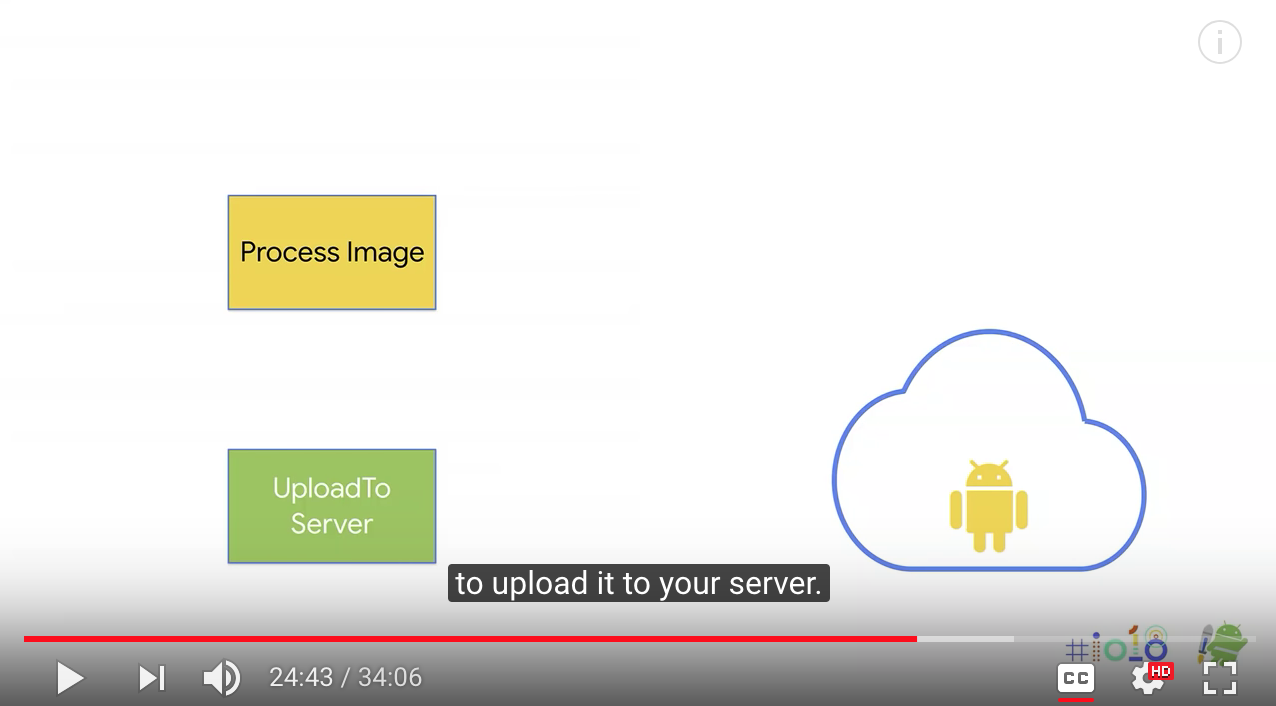
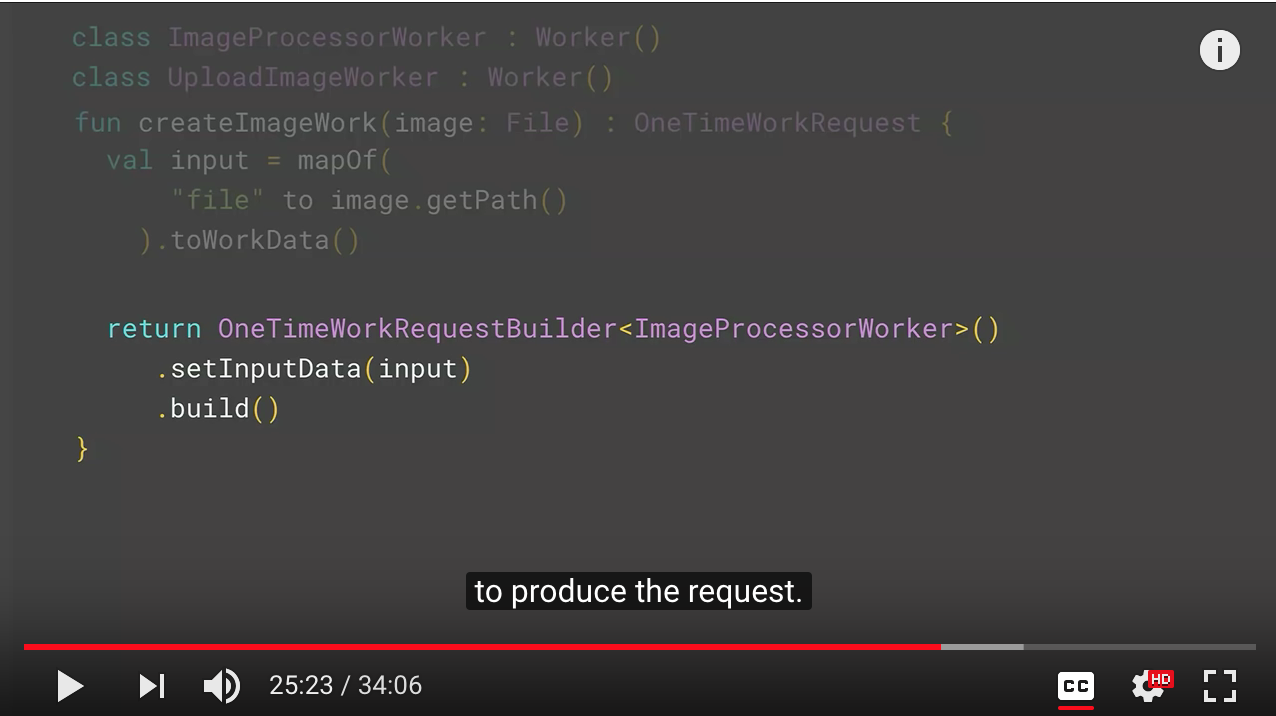
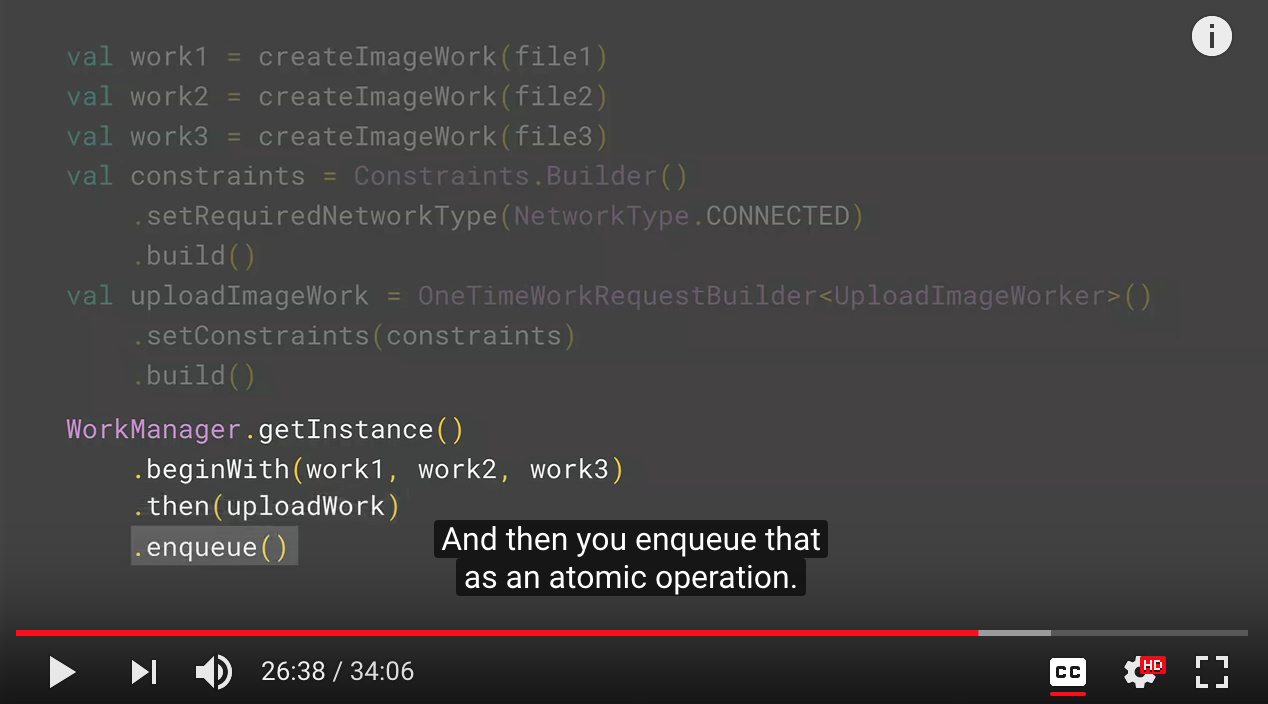
So we'll have two different workers. They all have single functionality. One of them does the image processing. The other one does the upload to server. OK, the helper function that receives an image file and creates the process image work request-- so it prepares the input, just uses the same builder to produce the request. And now we get that. Now we wanted our network upload to wait for the internet connection. So we set the constraint. We say, OK, wait for internet connection before trying to run this work request. And then create the upload image work using that constraint. Once we have them, you can tell WorkManager, OK, begin with the process image work. Once you are done, then run the upload to server work. And now you enqueue both of these as an atomic operation to the WorkManager. Now your device can restart. Anything can happen in between. We will take care of running the two.

worker in parallel the same way
You can also use this API extensively. Like, you could run image processing in parallel the same way. So if user pick multiple photos, you want to process all of them, but upload it to server while some of them are done. You can easily do that with WorkManager.

Opportunistic execution